
Cross-Modal Machine Learning as a Way to Prevent Improper Pathology Diagnostics

Why is analysis of medical images difficult?
Machine learning techniques are widely employed to aid doctors in diagnosing. Still, enabling precise image recognition and analysis can be a really painful experience. This blog post explores why it happens and seeks the ways out as discussed at TensorBeat 2017.
Dave Singhal talked about the challenges of applying machine learning to improve diagnostics. In particular, identifying good vs. bad pathologies to prevent unnecessary removal of an organ or dealing with pathologies that spread to different organs.

Image recognition in healthcare is anything but an easy task with indistinct edges, numerous tiny elements, low contrast, etc. In addition to that, medical data comes in multiple forms—MRI, sonograms, X-rays, etc.—with different modalities.
However, the spectrum of machine learning tools is diverse enough to address such tasks as:
- classification
- detection
- segmentation
- registration
- text + modality
- cross-modality
- image retrieval, generation, and enhancement
Cross-modal learning for image segmentation
Dave is enthusiastic about exploring the capabilities of what he refers to as cross-modal learning, which is “one model helping the other to do the analysis.” Dave exemplified the U-net architecture of a convolutional neural network that ensures fast and precise image segmentation.
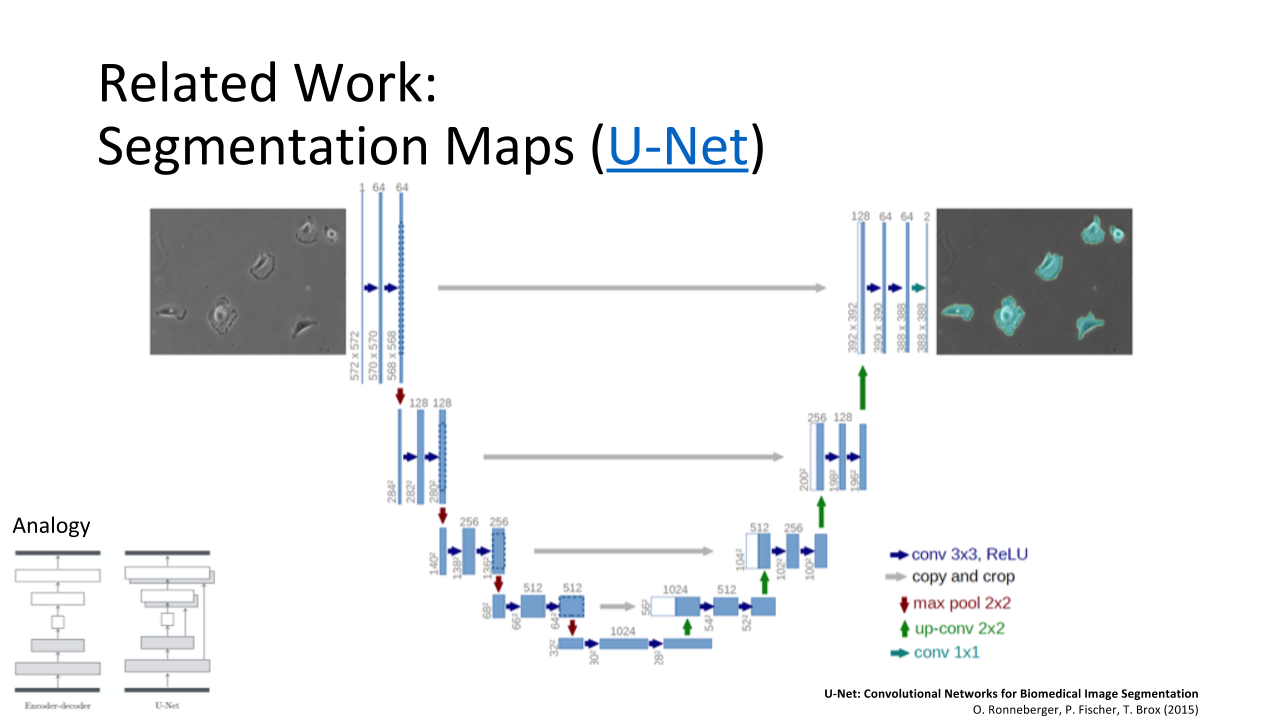
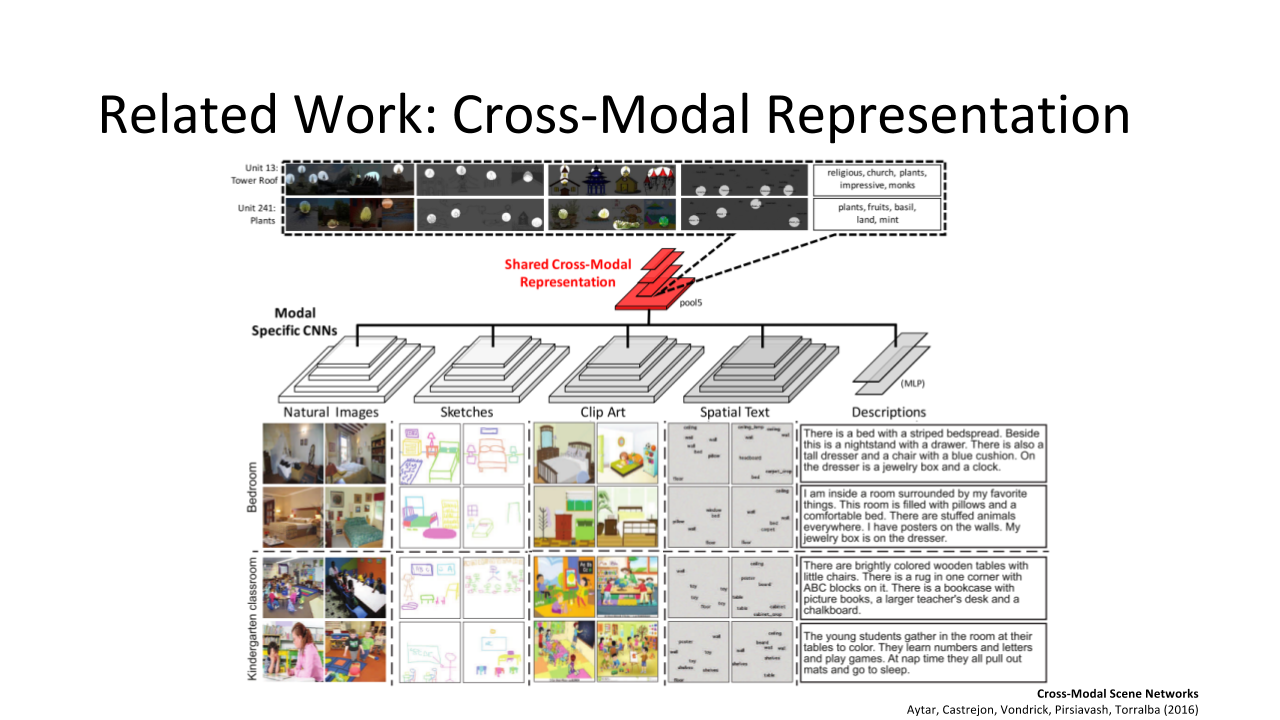
He also demonstrated what a shared cross-modal representation, which is a set of modal-specific convolutional neural networks, looks like.
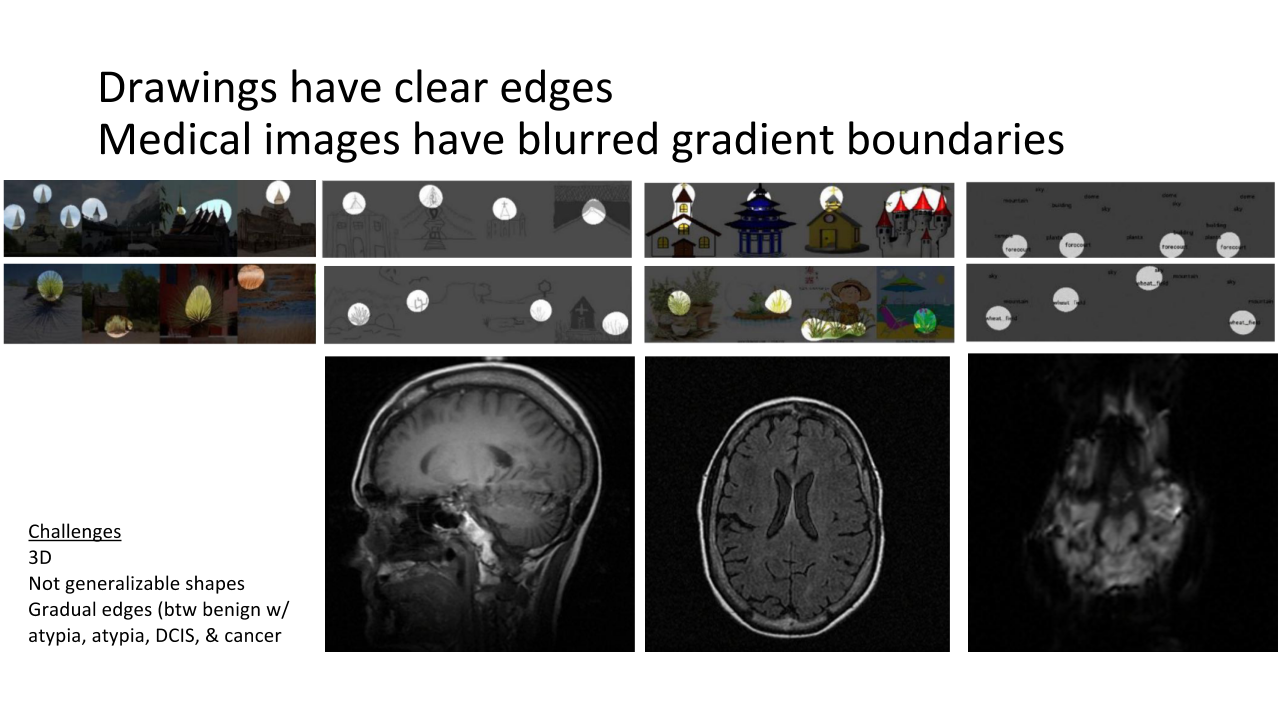
However, using such an approach for medical images is challenging as they hardly have sharp features, shapes are mostly not generalizable, edges are gradual, etc.
Dave concluded with an idea of using machine learning for:
- cross-segmentation, -representation, -retrieval, and -analysis
- cross-visual attention maps
- surfacing sub-perceptual (sub-threshold) features

So, machine learning is evolving to save even more lives through helping doctors to avoid mistakes when diagnosing pathologies of different complexities, while automating routine tasks.
Join our group to stay tuned with the upcoming events.
Want details? Watch the video!
Related slides
Further reading
- TensorFlow and OpenPOWER Driving Faster Cancer Recognition and Diagnosis
- Recurrent Neural Networks: Classifying Diagnoses with Long Short-Term Memory
- Experimenting with Deep Neural Networks for X-ray Image Segmentation
- Deep Learning in Healthcare, Finance, and IIoT: TensorFlow Use Cases
About the expert
Dave Singhal is an entrepreneur in imaging and machine learning. He is exploring multi-modal medical convolutional neural networks and advising Apricity Health in that area. At Stanford, Dave developed multi-user interaction on a pseudo-holographic display. He holds 10+ patents in areas including imaging, transcoding, displays, and medical image quality metrics.





