
Deep Learning for Cybersecurity: Identifying Anomalies and Malicious Traffic

A recent webinar discussed how deep learning solutions can be applied to deliver better cybersecurity. However, things don’t always come as we expect, so there are certain difficulties to solve. Steven Hutt, a consultant in deep learning and financial risk, digs into the challenges on the way and the approaches at hand to save the day.
Categorical data and other issues
In a view of exemplary data breaches experienced by such giants as Yahoo, Sony, and even Democratic National Committee, Steven emphasized the urgency of enhancing cybersecurity. While attack vectors are constantly changing and static detection approaches fail, deep learning can be employed to “better identify malicious network traffic.”
Still, things don’t come that easy. Though, there is plenty of data, and we observe steady progress in general areas of unsupervised feature and anomaly detection, hurdles are also to count:
- Practical usage of deep learning requires a very low false positive rate.
- Essentially no labelled data.
- Data is a hybrid of categorical (mostly) and numeric (some).
Steven introduced a notion of a network flow—“a record of the information exchanged via packets between a source and a destination machine during the course of the network protocol session.”
Network flow values are a mixture of categorical, numerical, and text data. With deep learning solutions for treating numerical and text data extensively developed, the main focus shifts to categorical data.
Generative models and multivariate distributions
In attempting to fit a probability distribution to the data, Steven suggest using generative models.

In contrast to numerical or text data, deep learning solutions that treat categorical data has been studied less. In his example, Steven demonstrated how to model multivariate categorical distributions. (Note: Multivariate distributions are probabilistic distributions, whose samples are represented as vectors.) According to him, every multivariate categorical distribution is a mixture of multivariate categorical distributions with independent marginals.
Though the mixture representation result is quite encouraging, there come up some challenges to address:
- Direct likelihood maximization is computationally very expensive.
- Stochastic gradient descent is not possible as variables are discrete.
- The indicated size of the mixing variable is geometric in the indicated dimension.
Tricks at hand
To eliminate the current issues, one may utilize:
A variational inference for approximate likelihood maximization
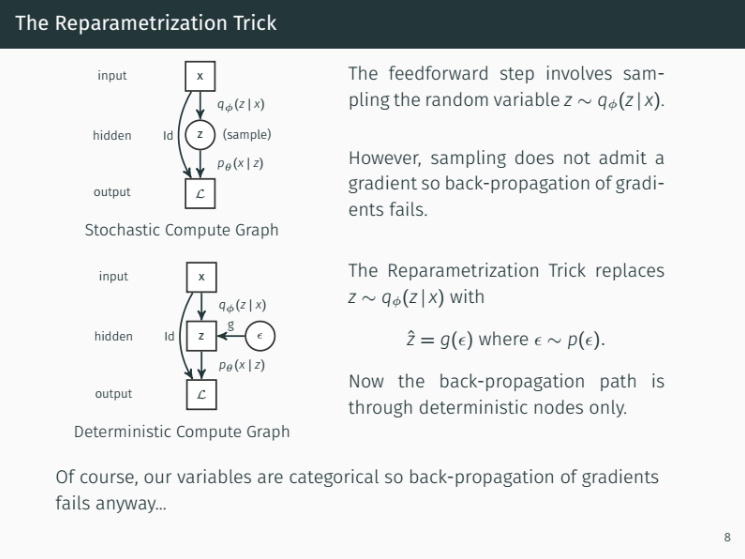 Reparametrization may fail with categorical variables
Reparametrization may fail with categorical variablesThe Gumbel softmax to relax categorical variables to continuous variables
 Sampling random variables with Gumbel’s distribution
Sampling random variables with Gumbel’s distribution- The Dirichlet processes to incorporate the indicated size of the mixing variable as part of the inference
At the webinar, Steven detailed how each of the approaches work. For more detail, watch the video recording of the webinar.
Related slides
Further reading
- The Diversity of TensorFlow: Wrappers, GPUs, Generative Adversarial Networks, etc.
- Cybersecurity for the IoT: Issues, Challenges, and Solutions
- Deep Learning in Healthcare, Finance, and IIoT: TensorFlow Use Cases (Videos)
About the expert
Steven Hutt is a consultant in deep learning and financial risk, currently working in cybersecurity and algorithmic trading. He has previously been head quant for credit at UBS and Morgan Stanley, and before that a mathematician dealing with an obscure branch of topology.




