
Hadoop Benchmark: Cloudera vs. Hortonworks vs. MapR

Evaluating Hadoop distributions across 7 workloads
Cloudera, Hortonworks, and MapR are the most popular Hadoop distributions available today. However, even with this short list, there are few unbiased comparisons of their cluster performance. So, today we are introducing a 65-page research paper that contains a vendor-independent overview of Cloudera, Hortonworks, and MapR distributions.

Vladimir Starostenkov of Altoros compared the throughput of 8-, 12-, and 16-node clusters against the performance of a 4-node cluster. (The speed values of data processing on 8-, 12-, and 16-node clusters were divided by the throughput of a 4-node cluster.) The results were quite unexpected.
Hadoop performance: bigger doesn’t mean faster
In a recent interview to TechTarget, our R&D Engineer Dmitriy Kalyada explained why adding nodes to a Hadoop cluster not always results in better performance. The new benchmark of Hadoop distributions confirms this behavior under several workloads.
For instance, when sorting unstructured text data (the Sort workload), the performance of a MapR cluster was growing linearly (as we were increasing its size from 4 to 8 nodes). After that, when new machines were added, the throughput of each separate node was degrading.
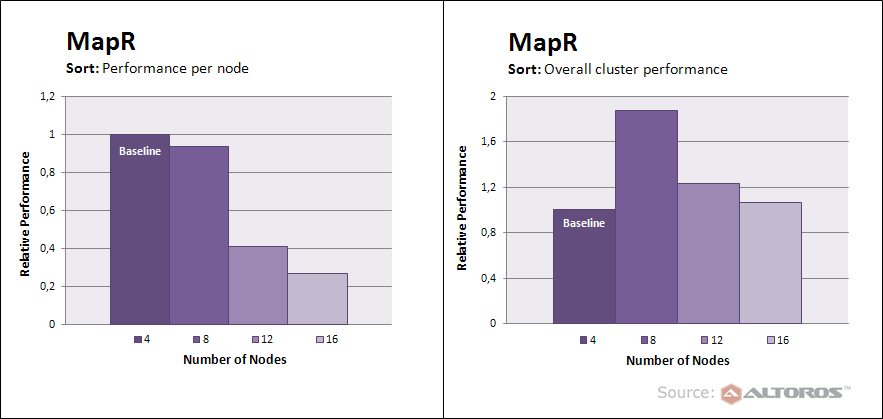 The MapR cluster performance
The MapR cluster performanceAs you can see on the diagram, an 8-node cluster turned out to be faster than clusters of 12 and 16 nodes. The same situation was observed in the DFSIO write test. Other Hadoop distributions had similar results under some of the workloads, too.
Download the benchmark to see all the performance results (83 diagrams, 7 types of workloads), including:
- detailed performance results for 4-, 8-, 12-, and 16-node clusters
- how the size of a cluster affects data processing speed
- what issues slow down deployment and how to maximize Hadoop processing speed
- how different clusters behave under CPU and disk-bound workloads (including Bayes, DFSIO, Hive aggregation, PageRank, Sort, TeraSort, and WordCount)
In the comments below, let us know what you think about the performance results.






