
Deep Q-networks and Practical Reinforcement Learning with TensorFlow

Making reinforcement learning work
What are the things-to-know while enabling reinforcement learning with TensorFlow? Illia Polosukhin, a co-founder of XIX.ai, provided certain answers to this question, as well as delivered some practical insights at TensorBeat 2017.
As Illia puts it, one doesn’t actually have to train data as part of reinforcement learning, but rather drive different types of observations form an environment, perform actions, etc.
To do so, one can employ OpenAI Gym, which is a toolkit for developing and comparing reinforcement learning algorithms. It features a library of environments for games, classical control systems, etc. to aid developers in creating algorithms of their own. Each of the environments has the same API. The library also enables users to compare / share the results.
Illia demonstrated a sample code of an agent acting within an environment.

He also showed the code behind an agent.

So, what makes it all work?
The set of states and actions, coupled with the rules for transitioning from one state to another, make up the Markov decision process (MDP). One episode of this process (e.g., a single game) produces a finite sequence of states, actions, and rewards.
What one has to define is:
- a return (a total discounted reward)
- a policy: the agent’s behavior (deterministic or stochastic)
- the expected return starting from a particular state (state-value function, action-value function)
Deep Q-learning
One of the ways to approach reinforcement learning is deep Q-learning—a model-free, off-policy technique. What it means is that there is no MDP approximation or learning inside the agent. Observations are stored into replay buffers and are further used as training data for the model. Being off-policy ensures that an optimal learning policy is independent of the agent’s actions.
Illia then demonstrated what the Q-network code looks likes.
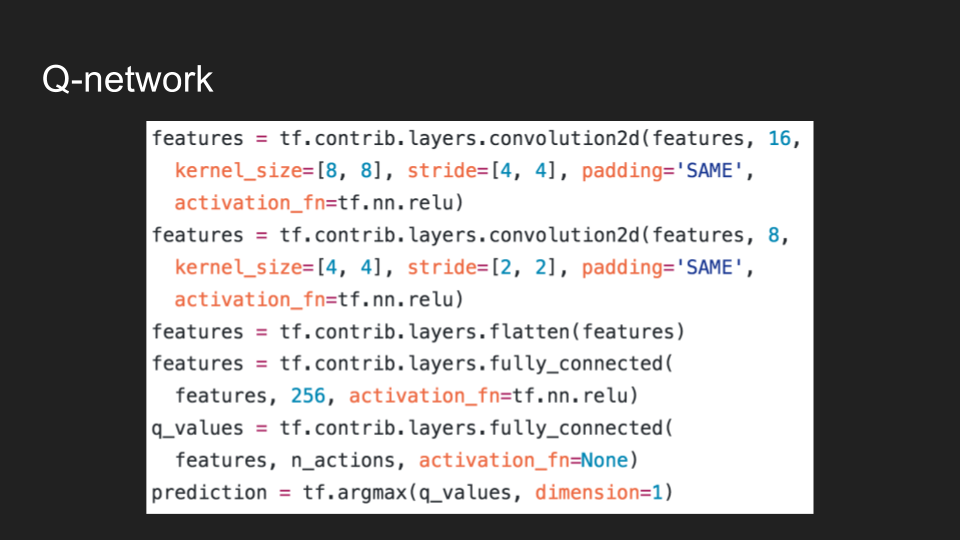
As well as how to run optimization.

More examples can be found in this GitHub repo.
As one of the tricks at hand when training a TensorFlow model, MonitoredSession can be employed for:
- handling pitfalls of distributed training
- saving and restoring checkpoints
- injecting computation into TensorFlow training loop via hooks
Asynchronous Advantage Actor-Critic
To enhance reinforcement learning, the Asynchronous Advantage Actor-Critic (A3C) algorithm can be used. In contrast to a deep Q-learning network, it makes use of multiple agents represented by multiple neural networks, which interact with multiple environments. Each of the agents interacts with its own copy of the environment and is independent of the experience of the other agents.
Furthermore, this algorithm allows for estimating both a value function and a policy (a set of action probability outputs). The agent uses the value estimate (the critic) to update the policy (the actor) more intelligently than traditional policy gradient methods. Finally, one can estimate how different the output is from the expected one.
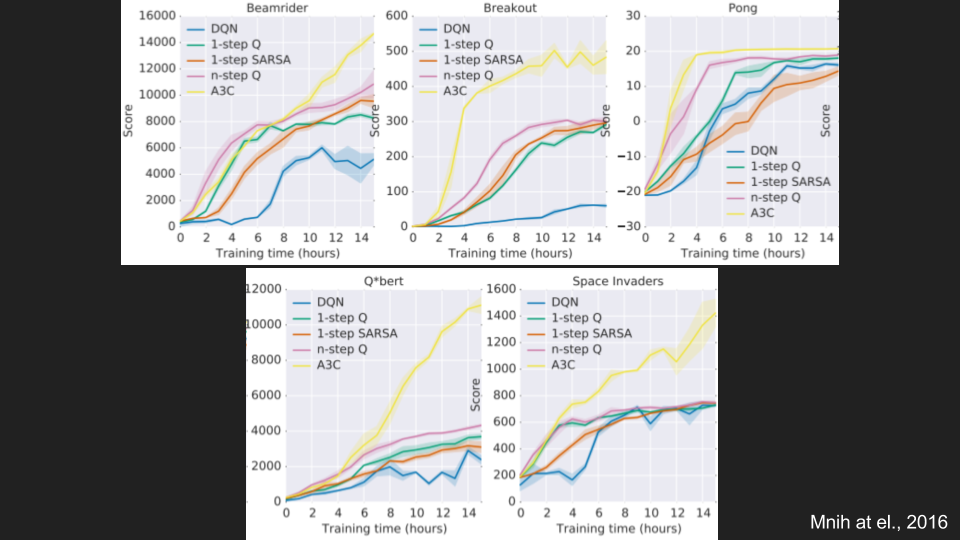
All the above mentioned can be applied in such spheres as robotics, finance, industrial optimization, and predictive assistance.
Join our group to stay tuned with the upcoming events.
Want details? Watch the video!
You can also check out the full presentation by Illia Polosukhin below.
Related session
At another TensorFlow meetup in London, Leonardo De Marchi (Lead Data Scientist at Badoo) also shared how to apply reinforcement learning within the gaming industry.
Below, you will find the slides by Leonardo De Marchi.
Further reading
- What Is Behind Deep Reinforcement Learning and Transfer Learning with TensorFlow?
- Learning Game Control Strategies with Deep Q-Networks and TensorFlow
- TensorFlow in Action: TensorBoard, Training a Model, and Deep Q-learning
About the expert
Illia Polosukhin is a chief scientist and a co-founder at XIX.ai. Prior to that, he worked as an engineering manager at Google. Illia is passionate about all things artificial intelligence and machine learning. He has gained master’s degree in Applied Math and Computer Science from Kharkiv Polytechnic Institute. You can check out his GitHub profile.




