
Text Prediction with TensorFlow and Long Short-Term Memory—in Six Steps

Continuous bag-of-words and skip-gram
The recent TensorFlow webinar focused on behind-the-scenes mechanisms of text prediction. In addition to using TensorFlow and long short-term memory networks for the purpose, the attendees learnt about two word2vec models for generating word embeddings, their concept differences, and employment.
Exploring the evolution of deep learning, Dipendra Jha and Reda Al-Bahrani exemplified some of the areas it is applied only within Google as one of major prodigies at the playground. So, thanks to deep learning, we can now search by image, enjoy individual YouTube recommendations, use online maps, and even enable an autopilot to drive for us.
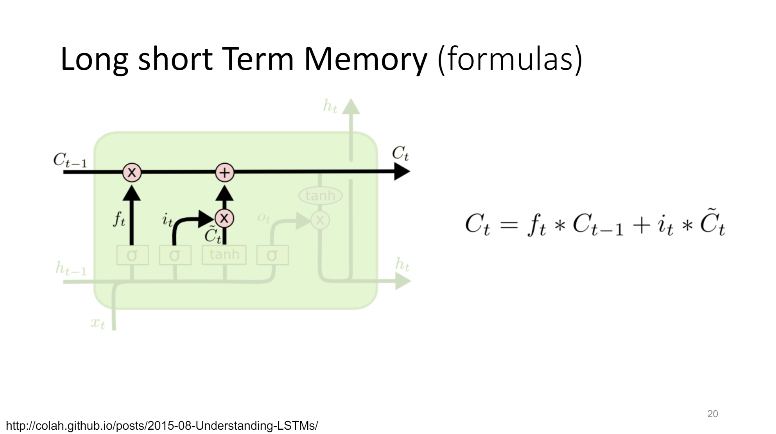
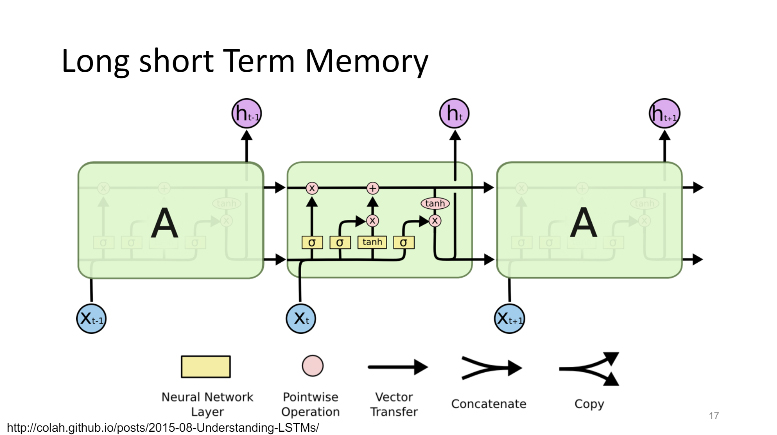
In the webinar, the presenters particularly focused on text prediction with recurrent neural networks (RNN), or long short-term memory networks (LSTM) to be specific, and TensorFlow. For instance, the speakers explained what mathematical formulae are behind the LSTM magic.
According to them, when generating word embeddings, one can make use of the two word2vec’s models: continuous bag-of-words (CBOW) and skip-gram.
In terms of underlying algorithms, both models are similar, slightly differing only in the approach: CBOW predicts target words from source context words, while skip-gram does the inverse and predicts source context-words from the target words. Simply put, the CBOW model uses surrounding words to predict the one of interest, while the skip-gram model uses the central word to define the surrounding ones.
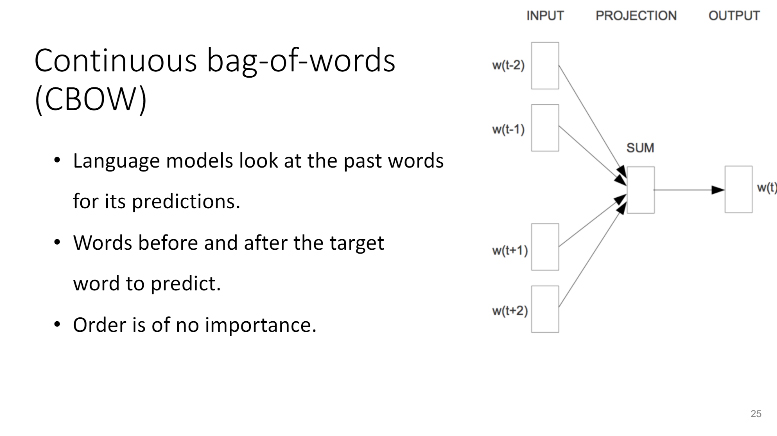
Other minor differences include an absence of a hidden layer in the skip-gram architecture and no strict rules for word order in CBOW. According to this TensorFlow tutorial, CBOW is more useful for smaller data sets, while skip-gram is more essential for larger ones.

Break it down to six steps
Then, Dipendra and Reda suggested six steps to take in the process of text generation:
- Clean data
- Build vocabulary
- Convert text to word vectors
- Define the model (encoder-decoder)
- Train the model
- Generate text
Within each of the steps, there are some particular things to accomplish. Thus, cleaning data spans tokenization, lemmatization, and stemming. For converting text to word vectors, the prerequisites are the following:
- a vocabulary of all the words used in input data
- a unique mapping of each word to an index
So, the input text can be converted to word vectors through using the word mapping.
When defining the model, one has to proceed with:
- using a word embedding to embed the input into 2D arrays
- using a decoder (with an encoder) comprising RNNs and LSTMs to make predictions
- applying some fully connected layers on top of the decoder output to generate the actual predictions
You can find the slides and the source code for each of the steps in Dipendra’s GitHub repo. For other details, check out the recording of the webinar.

Further reading
- Analyzing Text and Generating Content with Neural Networks and TensorFlow
- The Magic Behind Google Translate: Sequence-to-Sequence Models and TensorFlow
- Enabling Multilingual Neural Machine Translation with TensorFlow
About the experts
Dipendra Jha is a fourth-year Ph.D. Candidate in Computer Engineering at Northwestern University. At the CUCIS lab, Dipendra is researching the possibilities of scaling up deep and machine learning models using HPC systems, and on their application to accelerate materials discovery in the field of materials science and engineering. Prior to this, he completed his Master’s in Computer Science from Northwestern University.
Reda Al-Bahrani is a Ph.D. Candidate in Computer Science at Northwestern University. He is exploring the field of deep and machine learning in the CUCIS lab. His research focuses on knowledge discovery for health informatics from structured data and textual data. Reda worked in technical support for Saudi Aramco XHQ environment at Siemens Saudi Arabia before joining CUCIS. Prior to this, he completed his Master’s in e-commerce from DePaul University.





